作为实体经济的支柱产业,我国制造业有着悠久的历史和庞大的产业结构,产业链环节众多、复杂度高是制造企业供应链的典型特征,推进供应链的数字化转型之路也成为企业高质量发展的共同选择。通过决策优化智能供应链计划,制造企业可以建立更高效的精益生产计划模型和与之相适应的组织架构,有效减少库存,提高整个供应链计划的效率并优化计划结果,进一步达成生产精益、库存合理、人员优化等多重目标。
为了帮助制造企业在“VUCA(乌卡)时代”更好的筑牢供应链底座,以平稳穿越转型发展的周期,杉数科技今年3月面向工业智能制造领域推出决策优化产品–杉数数弈平台(LibraMind),为企业科学地制定短期和中长期排产计划,优化生产管理及作业流程,提升整个供应链的柔性与敏捷度,以适应快速变化的市场需求。日前,e-works记者对杉数科技副总裁兼工业线事业部总经理黄翔进行了专访,就智能决策在供应链优化中扮演的角色、智能决策落地的关键技术以及数弈平台的核心特点进行了解读。在黄翔看来,高水平的供应链管理一直是制造企业的核心竞争力之一,数字化浪潮下企业供应链正朝着需求响应更快、协同效率更高、数据更加开放的方向演进,以运筹优化和机器学习为基础的智能决策技术应用将加速供应链的重构,成为提升企业供应链水平的着力点和落脚点。
图 杉数科技副总裁兼工业线事业部总经理黄翔
全面智能化,属于供应链的基因进化论
随着智能制造如火如荼的展开,线上线下加速融合,以往制造企业靠库存拼销量,与经销商、供应商博弈价格差的供应链体系已成为过去式。黄翔表示在制造商、供应商、客户等多方加入下,供应链管理变得日益复杂。特别是对于大型、集团型企业而言,产业链供应链重构朝着区域化方向发展,上下游之间的关系愈发紧密,培育以自身为主的产业链条对于制造企业而言是一个重要的战略机遇。
美国著名经济学家克里斯多夫曾提出:“市场上只有供应链而没有企业。现在,真正的竞争不再是企业与企业的竞争,而是供应链与供应链之间的竞争。”在黄翔看来,导致供应链管理从掌握企业前进方向的“隐形之手”逐渐变为显而易见的“核心引擎”,主要在于以下两方面原因:
首先,是国内制造业一直存在但并没有很好呈现和重视的“隐性基因”:黄翔表示我国作为世界第二大经济体、世界第一制造业大国,拥有全球完整且规模庞大的工业体系、强大的生产能力、完善的配套能力。在数字经济时代,企业供应链已经不再是单一的 “链”状线路,而是呈“网”状结构,各系统和各角色互相连接,互相依存。例如汽车零配件厂商在完成某项生产营销活动时,不仅需要保证内部生产线高效运转,如生产决策、车间运转、库存物流,还需要与外部在配合上无缝链接,如上游原材料、零部件供应商,下游整车厂以及经销商、物流、消费者等,各方之间的交互越来越紧密和频繁。
其次,是云计算、物联网、人工智能等新兴技术为企业发展注入的“显性基因”:根据杉数科技积累的实践经验看,制造企业正在将传统的供应链管理方式与数字化技术相结合,以实现供应链整个过程的高效、智能和透明化。尤其是面对外部不确定的供应环境以及市场需求的多样化和细分化,促使制造企业直面由实时客户和消费者需求反向驱动的供应链协同,进而形成柔性和个性化生产制造闭环,最终大幅缩短交付周期。
在“隐性基因”和“显性基因”交织的共同作用下,国内企业正在从“制造”走向“智造”。这其中,无论是供应链转型的效率提升、弹性建设、实时优化还是面向未来的创新,都可以看到智能决策的身影。黄翔表示智能决策面向的产业链是在打通上下游企业信息流的基础上,实现将产业链上企业整体进行各种资源同一调配,形成更加深度与高效的协作关系。通过将企业供应链管理的实际问题化繁为简,用运筹优化的思维将动态的、多元的、大规模的变化要素进行量化和可视化,可以帮助企业找到真正优质的需求,并推进订单的高效执行和交付。
以某生物医药企业为例,其在发展过程中一直推行精益生产策略,以实现“零库存”为目标。但前些年在疫情刺激下市场需求波动严重,短期内会出现大量“插单”现象,由于追求极致库存导致该企业在处理紧急订单时,给后端生产、物料、运输等环节带来了诸多压力,企业履约成本直线上升,进入了生产规模增长但整体利润率踌躇不前的窘境。
在双方多轮沟通交流下,此生物医药企业与杉数科技在其计划与运营的数字化、智能化方面达成合作,共同打造了协同优化、智能决策平台。利用算法优势,该企业不仅在供给侧能够对市场进行预测,实现供应与需求的良好匹配;还可以从需求侧观察紧急订单的处理是否合理,根据车间工艺及生产限制,统筹平衡整体资源及物流规划,精准制定出企业利益最大化的排产计划,使企业订单达成率提升的同时综合节省成本约百万/年。
智能决策,从更广的维度重塑供应链价值
回过头来看,该生物医药企业携手杉数科技的供应链优化之旅固然令人振奋,但它在转型之前面临的痛点问题也同样值得重视。对于制造企业而言,无论是从销售预测上考虑突发事件对订单量的影响、到生产计划层面考虑对工厂产能的影响,乃至突发事件对断供的影响……供应链上任何一环的细微波动,都会扩大成影响上下游的涟漪:
在以市场为导向的今天,传统大批量订单以获得生产成本优势的模式已过时,企业如何适应市场需求的改变,即小批量、多批次的生产制造诉求?
紧急插单会改变其他订单的交付计划,进而影响整体收益,企业如何以全局性思维判断插单对于企业的综合影响?
在企业的核心产品生产上,如何应对需求和供给的高波动性,将可能出现的供应链断点带来的冲击降到最低?
诸如此类的问题还有很多,黄翔表示受限于技术条件,很多制造企业对于市场需求的判断、生产计划的排程、供应链上下游的管理是割裂的,很多生产要素无法量化考虑,高层领导在进行决策时在“大局观”的影响下难免顾此失彼,无法把所有因素都考虑进去,对企业订单实现精细化的管理。
“这也是为什么杉数科技将求解器对模型进行运筹优化和求解,首先应用在制造业供应链系统的重要原因之一。”黄翔表示供应链的高度复杂性决定了企业需要在物料、人员、设备等多维度进行计算和优化。从实现价值上看,有效的运营管理不会只局限于规划或计划本身,其作用传递到不同的生产运营环节,都会为企业带来更多实质性的业务收益。
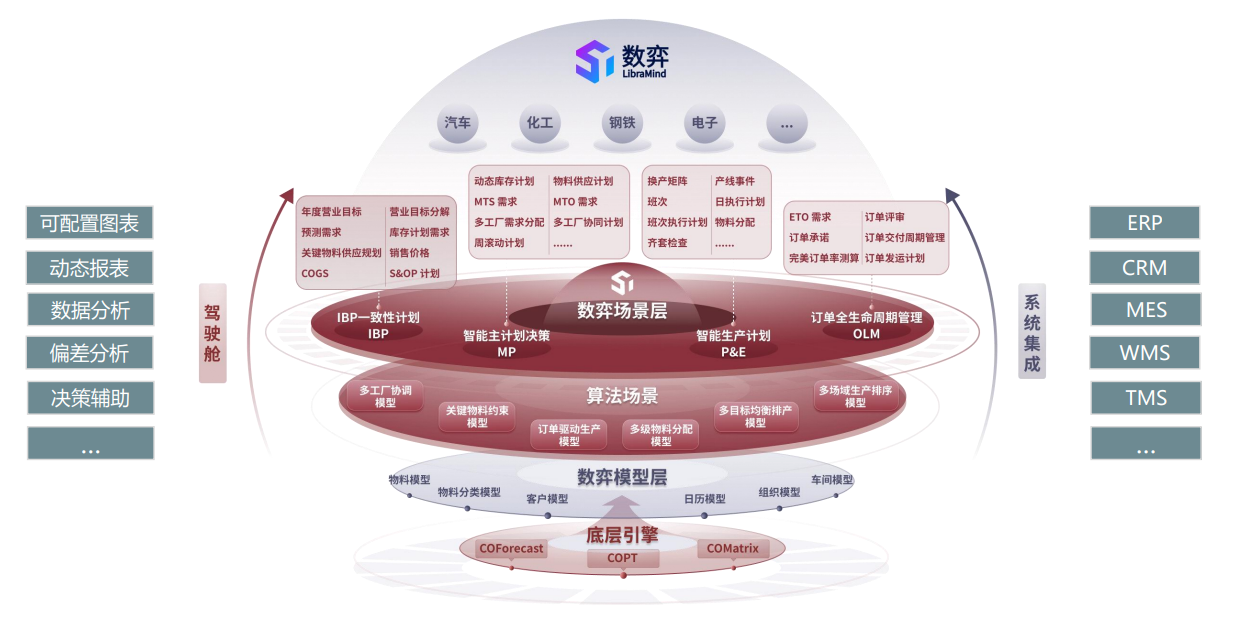
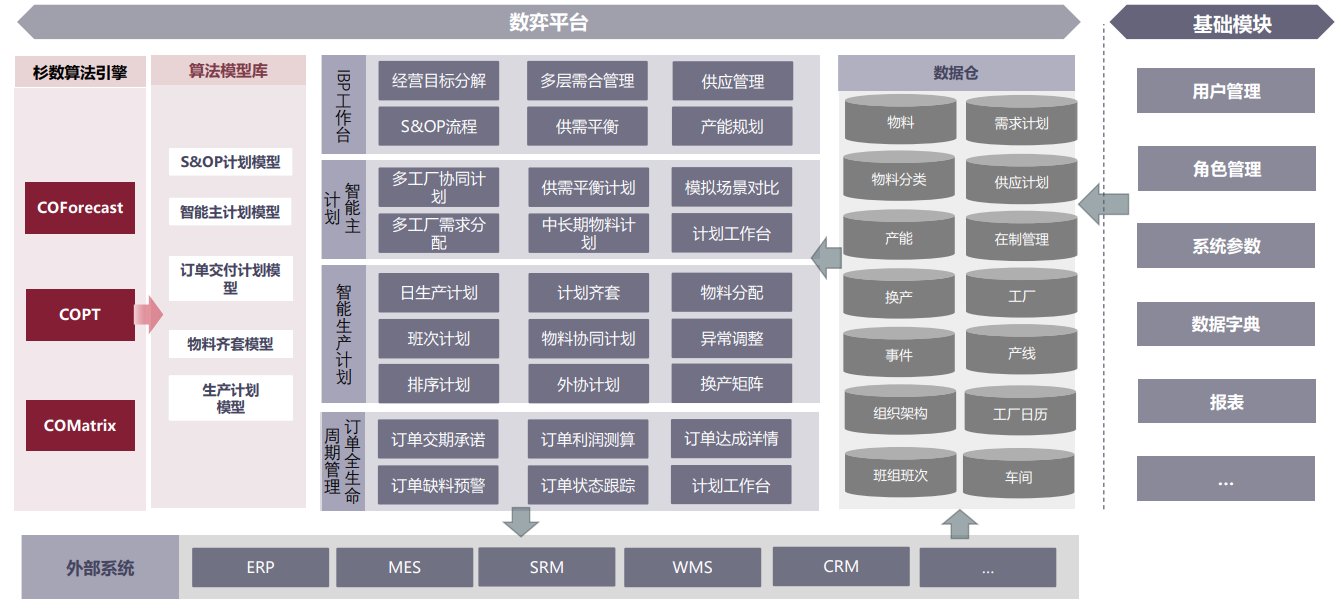
图 杉数数弈(LibraMind)工业智能制造决策优化平台架构图
值得一提的是,黄翔强调与火爆出圈的ChatGPT不同,AI大模型要发挥价值,不管是商业价值还是社会价值,关键的一点是输出的结果必须是可信的。当AI应用于严苛的制造环境时,无论是研发端的生成式创新还是针对产线的工艺优化,一个微小的不可控错误就会造成灾难性的后果。对于制造企业而言,在应用智能决策的过程中,离不开发方法论指引,也离不开场景选择、业务逻辑的深入理解,更离不开机器学习和运筹学技术的深度融合。
例如同样是对底层业务建模,杉数科技的数弈平台会针对企业实际经营情况,经过数据描述和清理、规律分析、决策分析层层递进,高保真的构建一个全维度的智慧型框架,最终实现多目标多约束“最优解”。
深耕场景,专为满足客户实际需求而生
无论是何种应对策略,多变且不稳定的外部形势是客观存在的。目前,有些企业虽然搭建了各种大大小小的平台和中台,但成效甚微,数字化投入产出比并不理想,其根本原因在于没有适配对应的场景,甚至很多供应链管理的战略细则只在企业高层的头脑中,无法落实到企业的日常生产、运营工作中。
“这也是为什么杉数科技发布的数弈平台在瞄准智能决策和数据驱动外,特别强调场景的融合和行业的划分。”黄翔介绍“引擎+决策中台+场景”一直是杉数科技发展的核心策略,而“场景”将成为杉数科技今年的战略重点。“当我们聚焦企业供应链的时候,会发现不同领域的客户存在着不同细分、碎片化需求。杉数科技会从数据、运营、创新等多个视角,设计与中台匹配的组织架构、业务流程和运营模式。”黄翔表示通过深耕用户场景,杉数数弈平台可以从供应链全生命周期降低因变化给企业发展带来的不稳定性,为企业数字化发展的持久性夯实组织和管理基础:
首先,杉数数弈平台会基于算法和业务为企业构建数字化产销总体规划,建立动态的中长期多层级联动计划,为产销提供不同目标的决策选择,同时提高决策质量并跟踪监控计划执行数据,以达到优化业务、提升运营效率的整体目标。例如面对近年来的制造企业“出海”热潮,杉数数弈平台支持对于多地区的统一数据信息管理,提供了涵盖各工厂需求、供应和财务信息的完整计划模型,可结合当地的区域要求和供应商能力,一键式生成包含需求计划、生产计划、库存计划、采购计划的计划群,实现跨组织的协作和产销的平衡。
当需要将主计划进行分解时,杉数数弈平台将生成精确到日/班次的产线级生产计划,同时考虑生产实际执行情况对计划的影响,进行滚动排程,确保计划结果的准确性和可执行性,并且数弈生产排程模块可以根据企业目标进行最优化排程,得到目标导向的最优排产结果。
在订单管理层面,杉数数弈平台会综合所有已签订的未完结订单需求,结合实际现有产能和未来产能规划,生成包括订单交付日期和交付数量的详细计划,在考虑企业现有生产能力基础上,智能快速进行订单测算,在较短的时间范围内生成订单交期回复结果,能够迅速响应客户需求,提高客户满意度。
针对物料计划,杉数数弈平台会根据需求计划及BOM数据,逐层拆解需求,考虑层级间的提前期和比例关系,计算得到各级物料的需求时间和需求数量,生成物料需求计划,并以中长期预测作为需求输入,同时考虑长期产能计划约束、物料齐套约束,驱动指导物料长期采购计划的制定。
图 杉数数弈平台功能架构图
在黄翔看来,制造企业的核心竞争力必定围绕着其专属know-how,与企业核心业务知识和数据息息相关。也正因为如此,杉数科技在数据驱动和场景化应用上下足了功夫。目前,杉数科技聚焦钢铁、化工、汽车、3C电子、新能源等制造行业,深度挖掘其内外部数据价值,形成战略、经营、利润目标,跨部门的一体化决策,进而解决生产制造过程中的大规模复杂决策、规划、调度、分配等问题。
补链强基,助力国内制造企业走向高质量发展
随着“近岸生产”和“制造网络多元化”逐渐成为企业的优先策略,制造业产业链分工日益深化。国内制造企业对于供应链愈发重视,领先的制造企业需要权衡韧性和效率,以确保自身供应链系统的有效运行。早在2017年,国务院办公厅就印发《关于积极推进供应链创新与应用的指导意见》,高度重视“强链、补链、固链”建设。在“十四五”规划纲要中,则明确提出强化资源、技术、装备支撑,推进制造业“补链强链”。
黄翔介绍以智能决策技术为抓手,正在成为很多“链主”企业资源优化配置的利器。他强调“链主”在集合产业链上不同规模企业的生产、供需环节时,通过智能决策技术可以更好的发挥“链主”企业的引领支撑作用,促进供需匹配,带动链上企业协同发展。例如“链主”可以站在整体产业链的视角审视整个流程、运营场景,并以客户和市场为核心,有的放矢,进行业务和服务创新设计和规划,实现前瞻性规划、高柔性响应意见多目标优化,让整个产业链协同效率更高、柔性更强。
实际上,在过去7年时间里,杉数科技服务了超过20个细分行业数百家国内外头部企业,进一步提升了各行业“链主”企业的产业竞争力,通过协同创新形成更多比较优势,确保对市场供应链的整体把控能力,与产业链上下游企业共同提高效率、改善效益。
图 杉数科技服务各行业客户代表
数字化转型是传统业务和技术的融合,经过疫情洗礼后的制造业供应链管理也悄然发生着变化。可以预见的是,随着人工智能、工业物联网等技术的广泛应用,未来企业与企业、企业与消费者之间的联系会更加紧密,深层融合下智能决策的应用场景将进一步拓展,数据的显性化、模型化也将进一步提速,制造企业将更加积极的应用智能决策技术。“杉数科技会重视每一个客户,为其打造基于智能决策的最佳实践,帮助制造企业平稳穿越发展周期,更加从容地应对供应链转型的时代挑战。”黄翔总结道。

BC810K01